Research
The primary object of this project is to improve the reliability of reservoir models for prediction and uncertainty analysis by extracting the maximum amount of information from the 4D data and assimilating it for accurate uncertainty estimation.
To achieve the primary objective, we have identified four secondary objectives:
- Model verification develop efficient methodologies for assessing the quality of history matched models and probabilistic forecasts on large problems,
- Model improvement develop and assess methods for identification of missing parameters, missing processes, and parameters for which the prior uncertainty is not well represented,
- Model calibration further develop methods for conditioning models to observations such that errors in forecasts are reduced and uncertainty is properly quantified,
- Robust work flow develop a standard work flow for 4D seismic history matching with reduced model error and better forecast ability.
Model error is an inherent problem in all real-world applications of data assimilation, including assimilation of seismic data into reservoir models. Common sources of model error include non-representative distributions of initial geomodels, neglect of processes and sub-grid heterogeneity in reservoir simulation models, simplification of petro-elastic models, and overly simplistic simulation of seismic attributes from reservoir flow models. To reduce the effects of model error, it is necessary to diagnose its presence, identify the sources of model error, and improve modeling of prior uncertainty.
In Work Package 1, lead by Dean Oliver, we develop methods to provide quantitative checks on the consistency of the model for history matching of data and for reliability in forecasting. The objective of model checking is not to determine if the model is misspecified but rather to examine the consequences of model misspecification on predictions. The most common model diagnostics used in the petroleum industry have been an evaluation of the coverage of the data by the ensemble of calibrated models and a normalized magnitude of the data mismatch, but this is not a sufficient diagnostic in realistic cases. If, based on evaluation of model diagnostics, a model has been judged to be deficient, then it is often necessary to improve the model. In many cases, the source of much of the bias is the neglect of important parameters or physical processes. Identification of those missing parameters can be a key aspect of model improvement for greater forecast reliability. We are developing models that are better able to assimilate information from data by being less restrictive than traditional expert priors. We take advantage of weakly informative priors, hierarchical models, and multiple scenarios.
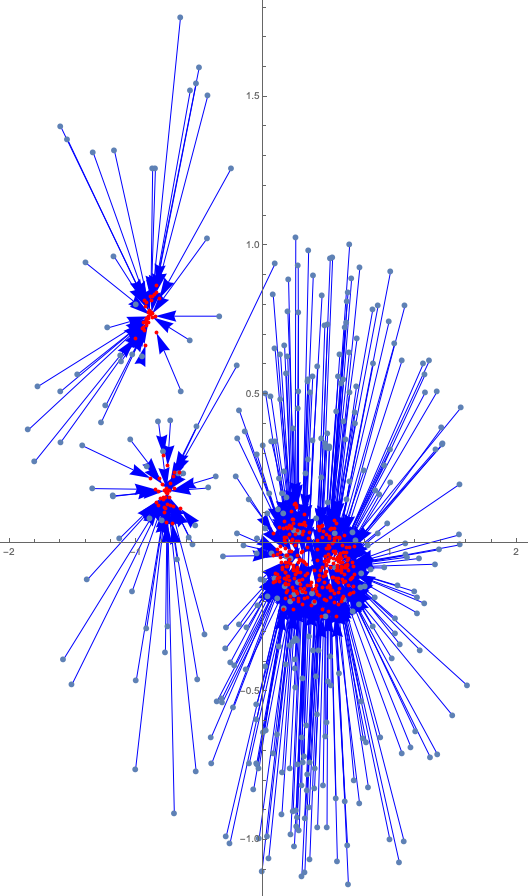
In Work Package 2, lead by Kristian Fossum, we make improvements in the algorithms for data assimilation, particularly with regards to assimilation of large amounts of data with small ensembles of models. It has recently been shown that a combination of data coarsening and inexpensive coarse-level reservoir simulations give very good results and often outperform alternative methods when an appropriate coarsening level is selected. We will develop a methodology for multilevel assimilation of inverted seismic data, that is, multilevel data representation combined with multilevel reservoir simulations, thereby avoiding the need for selection of one particular right level of coarsening. Also, when the prior probabilities are based on the possibility of multiple scenarios, evaluation of the Bayesian model evidence (BME) for model selection can be unstable, and is extremely computationally expensive for large problems with correlated data-errors as it involves calculation of the inverse of the data-error covariance matrix (precision matrix). We are developing methods for stabilization of BME calculations, and methods for computationally feasible calculation of large precision matrices. Another approach to dealing with parameters for which distance-based localization is not appropriate is through the use of adaptive localization. We are developing an implementation which projects the representation data onto an ensemble sub-space, and conducts localization based on the correlations between model variables and projected data.
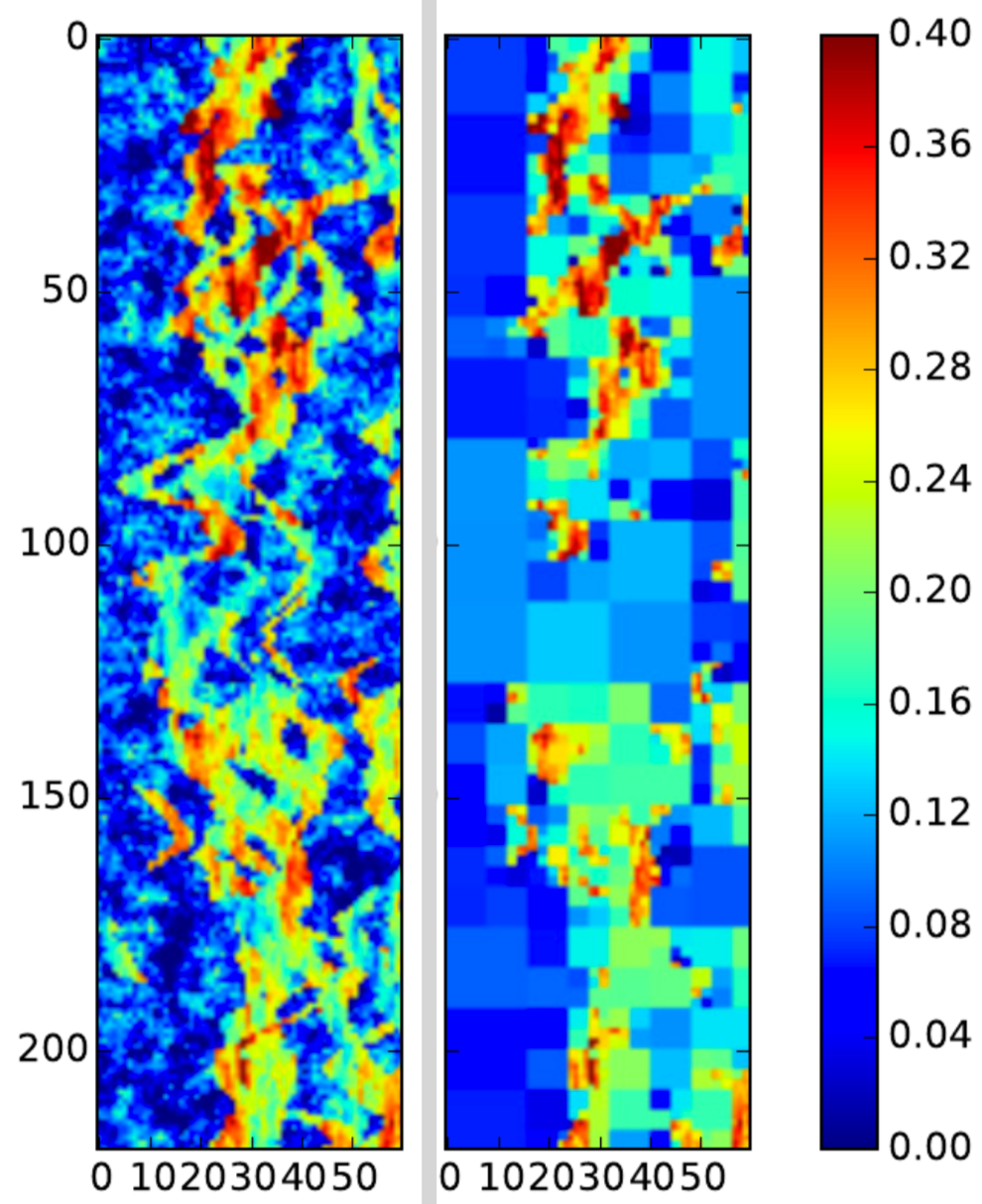
In Work Package 3, lead by Tuhin Bhakta, the focus is on robust and flexible work-flows for seismic history matching, including assessment of the quality of the 4D seismic data before assimilation of the data into the models. Forward modeling of 4D seismic response (Sim2Seis) consists of petro-elastic modeling and seismic modeling. In many history matching studies, the forward modeling is too simplified to provide modeled data that are sufficiently close to the observed 4D data/ attributes. Thus, the potential value of 4D information for model update is reduced. To capture effects of sub-grid heterogeneity on the predicted seismic attributes, it is necessary to integrate fine scale information from the static geomodel with the dynamic information from the reservoir model. Selection of an appropriate seismic attribute is essential in a successful history matching workflow since not all seismic attributes are sensitive to all reservoir states. Further we might need to re-parameterize the attributes to use them efficiently in HM. We are studying the information of various seismic attributes and their advantages and disadvantages in ensemble-based history matching for optimal information extraction.
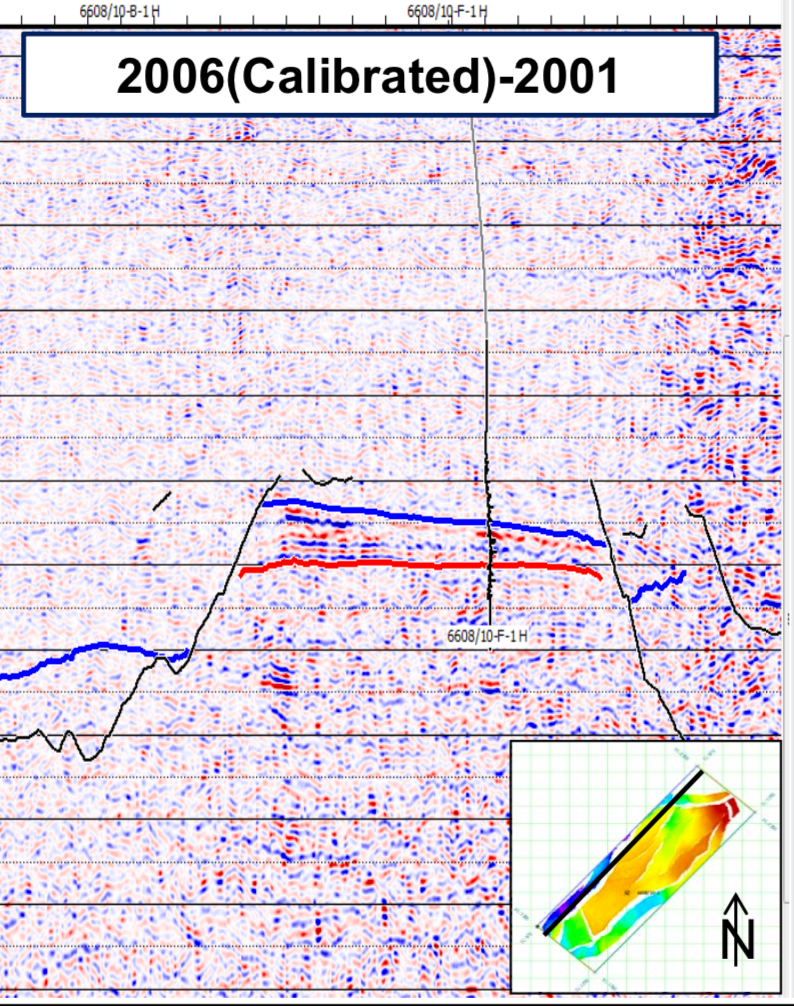
In Work Package 4, lead by Rolf Lorentzen, all methodologies and work flows developed in this project will be applied to real 4D seismic history matching problems. We will be using a field case with suitable complexity and sufficient data quality from industry partners to test many aspects of the new data assimilation methodologies developed in this project. Although we may look at multiple data sets, potential partners have indicated a preference for a single detailed study over multiple shallow studies.